Background
As a new graduate student looking for a project, I was introduced to Sloppy Models by my then-to-be advisor, Jim Sethna. Jim's group had been studying what they called "Sloppy Models," which are multi-parameter models with an extreme insensitivity to large-scale fluctuations in many parameter combinations. A good example of a sloppy model comes from systems biology. Protein signaling models often have many unknown parameters corresponding to things like reaction rates and Michaelis-Menten constants describing the complex interactions of a network. In fact, Jim's group had found that systems biology models were almost universally sloppy. They also observed sloppiness in such diverse models as quantum monte carlo variational wave functions, radioactive decay, insect flight, particle accelerators, and many more. For more information about sloppy models, you can visit Jim's webpage here, which has a lot of interesting information about sloppy models.
Is Sloppiness Intrinsic?
What intrigued me about sloppy models, was their apparent ubiquity in multi-parameter modeling. Surely there must be some unifying principle tying these very different models together.
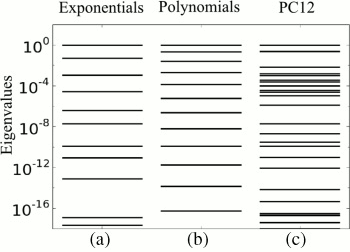 |
| Sloppy Eigenvalues. The eigenvalues of these models are more or less evenly spread out over many orders of magnitude. These eigenvalue spectra are characteristic of sloppy models. More information here. |
On the other hand, there seemed to be a very convincing argument (to me anyway) that sloppiness couldn't be anything profound. Sloppiness is identified by considering the sensitivity of the model behavior to changes in the parameters. This is measured by calculating derivatives of the model with respect to parameters, assembling these derivatives into a matrix (i.e. the Fisher Information Matrix) and calculating its eigenvalues. If the eigenvalues span several orders of magnitude (typically more than 6) the model is identified as sloppy. However, suppose we take a sloppy model with parameters θ1 and reparameterized the model to use new parameters θ2, where the two parameterizations are related by some function θ 1 = f(θ2). By an appropriate choice of the function f, you can always change the eigenvalues of the model's Fisher Information matrix to be any positive values you like. This suggests that sloppiness is a property of a model's parameterization and not the model itself. The fact that so many models seemed to be sloppy, would then mean that either most paramerizations were sloppy or that modelers were just very unlucky in their choice of parameters.
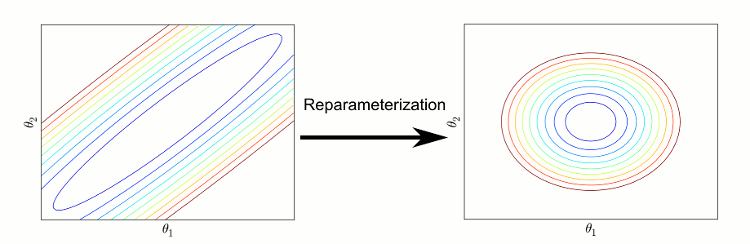 |
| Sloppiness and Reparameterization. Contours describing change in model behavior in parameter space (least squares cost) have long narrow canyons. (See Jim's site on sloppy models for more information.) By reparameterizing the model to rescale the canyon, the sloppiness is apparently removed. |
Although Jim's group identifies sloppiness from the eigenvalues of the Fisher Information (which depend on the parameterization) Jim speculated that these models also had common intrinsic features, i.e. features that were true for all parameterizations. In order to look for these properties, Jim suggested we use differential geometry since it provided a formalism to describe parameterization independent features. In fact, there is an entire branch of statistics, Information Geometry, devoted to this very subject. The project that I took up, and became a big part of my dissertation, was then the use of Information Geometry to study sloppy models.
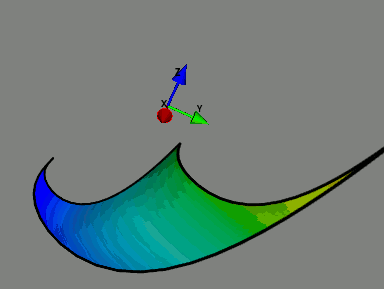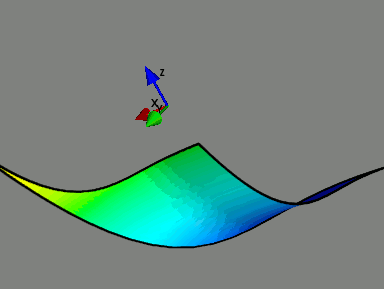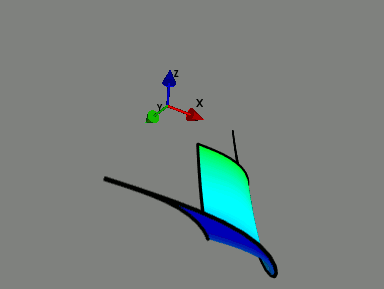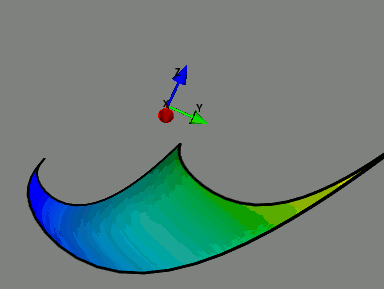 |
| The Model Manifold. A model can be associated with a manifold in data space with parameters as coordinates. This is an example of a manifold for a two parameter exponential model embedded in a three dimensional data space. This model has three boundaries corresponding to the physical limits of the parameters. Boundaries are universal feature of sloppy model manifolds. |
Discoveries
Studying sloppy models using differential geometry turned out to be very insightful. There were, in fact, several intrinsic features that sloppy models had in common. The models' manifolds are typically bounded and their widths form a hierarchy. In our mind's eye, we picture these manifolds as high-dimensional generalizations of a ribbon. A ribbon has a long dimension (length), a shorter dimension (width), and very small dimension (height). The model manifolds appeared to have a long dimension, a shorter dimension, an even shorter dimension, another even shorter dimension, and so on. We described these manifolds as a hyper-ribbon. We also observed that these models had universal characteristics in their curvatures.
Not only did we observe bounded manifolds in our sloppy models with similar curvatures, we were able to show, using theorems from interpolation theory, that such boundaries and curvatures should be a very general feature of multi-parameter models as long as the model predictions are relatively simple. This leads us to think of models as generalized interpolation schemes. This perspective helps explain the ubiquity of sloppy models. Model behavior can typically be constrained with just a few parameter combinations corresponding to the main features of the behavior. The remaining parameters combinations are irrelevant.
Practical Applications
The problem described above sounds very vague and abstract. However, it turns out to have many useful applications. As a graduate student, I worked to improve algorithms for fitting models to data. Jim's group had found that existing algorithms would struggle to find good fits. Their experience suggested the problem was closely tied to sloppiness: the insensitivity of the model to some parameter combinations seemed to give the algorithms fits. Often, they would require a lot of human guidance in order to converge. Since these models are often very large and expensive to compute, the entire fitting process could take a long time. Our goal was to use the parameterization-independent approach of differential geometry to motivate algorithms to improve the fitting process.
More generally, understanding the differential geometry of sloppy models tells us a lot about other, related problems. It can tell us a lot about the cost surface which in turn can be used to select methods of sampling in an MCMC calculation. It can be used to design experiments to more accurately infer parameters. It leads to a method of coarse-graining models with many parameters to describe simple emergent behaviors. Many of these applications we did not anticipate, but taken collectively suggest that thinking about modeling as a geometric problem is a very powerful and useful approach!